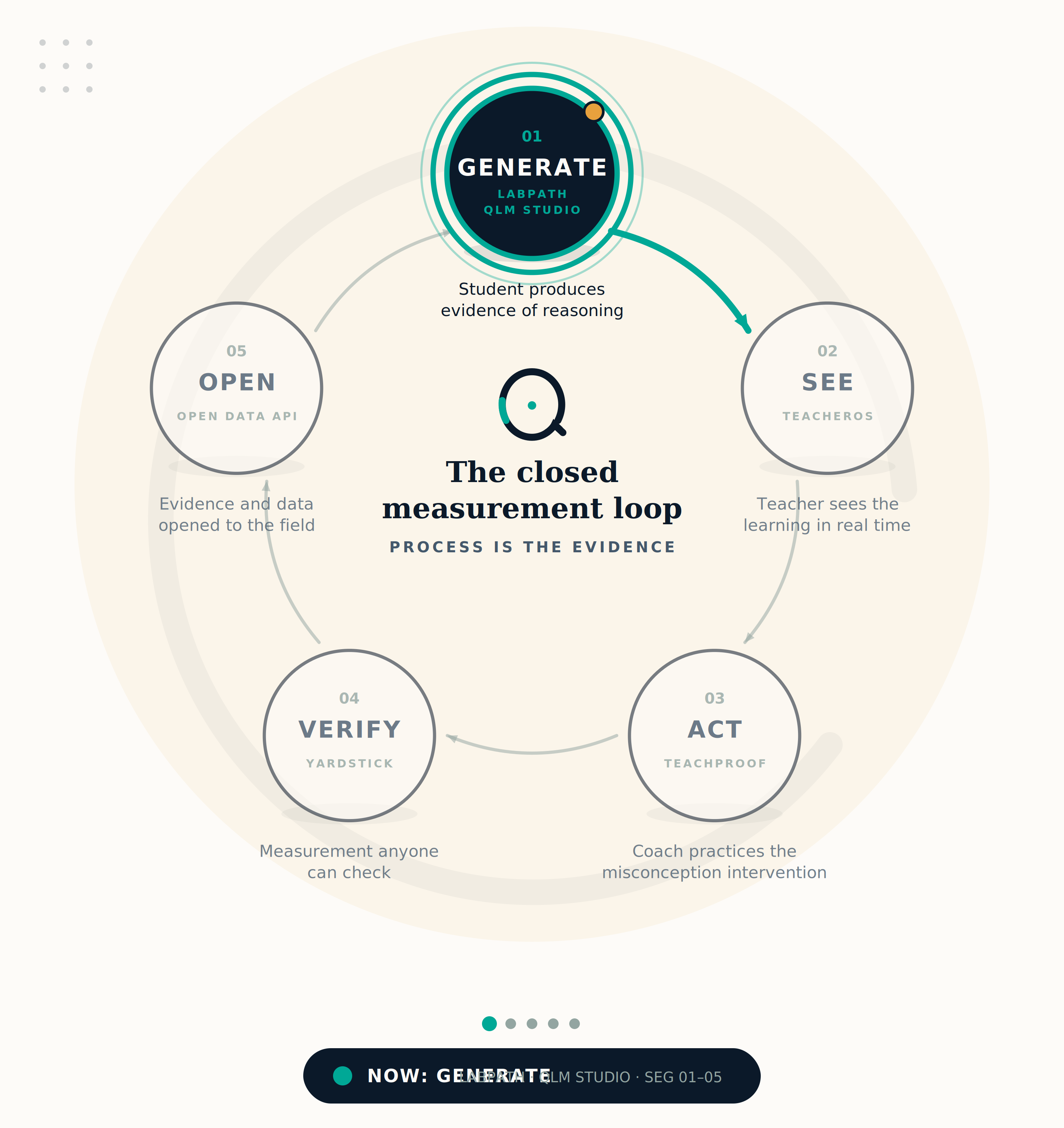
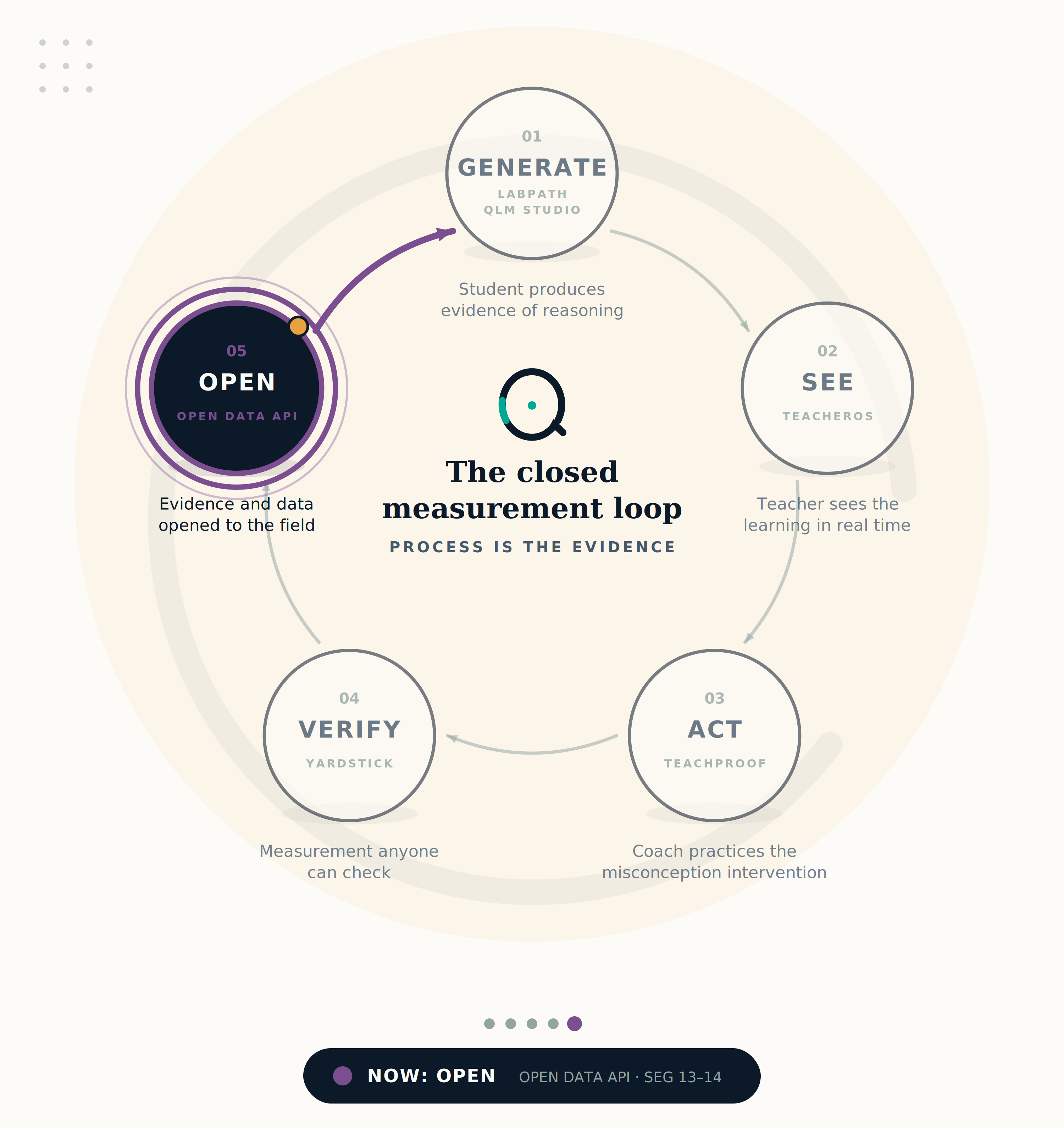
The closed measurement loop.
Students generate evidence. Teachers see it. Coaches act on it. Measurement anyone can check. Data opened to the field.

Students generate evidence. Teachers see it. Coaches act on it. Measurement anyone can check. Data opened to the field.
AI broke the assumption that a strong product proves a strong learning process. We measure the process — and we let anyone check the measurement.
Read the manifesto →LabPath puts students inside 47 hands-on STEM worlds where every action, prediction, and revision is captured as structured evidence — not a score, but a record of thinking.
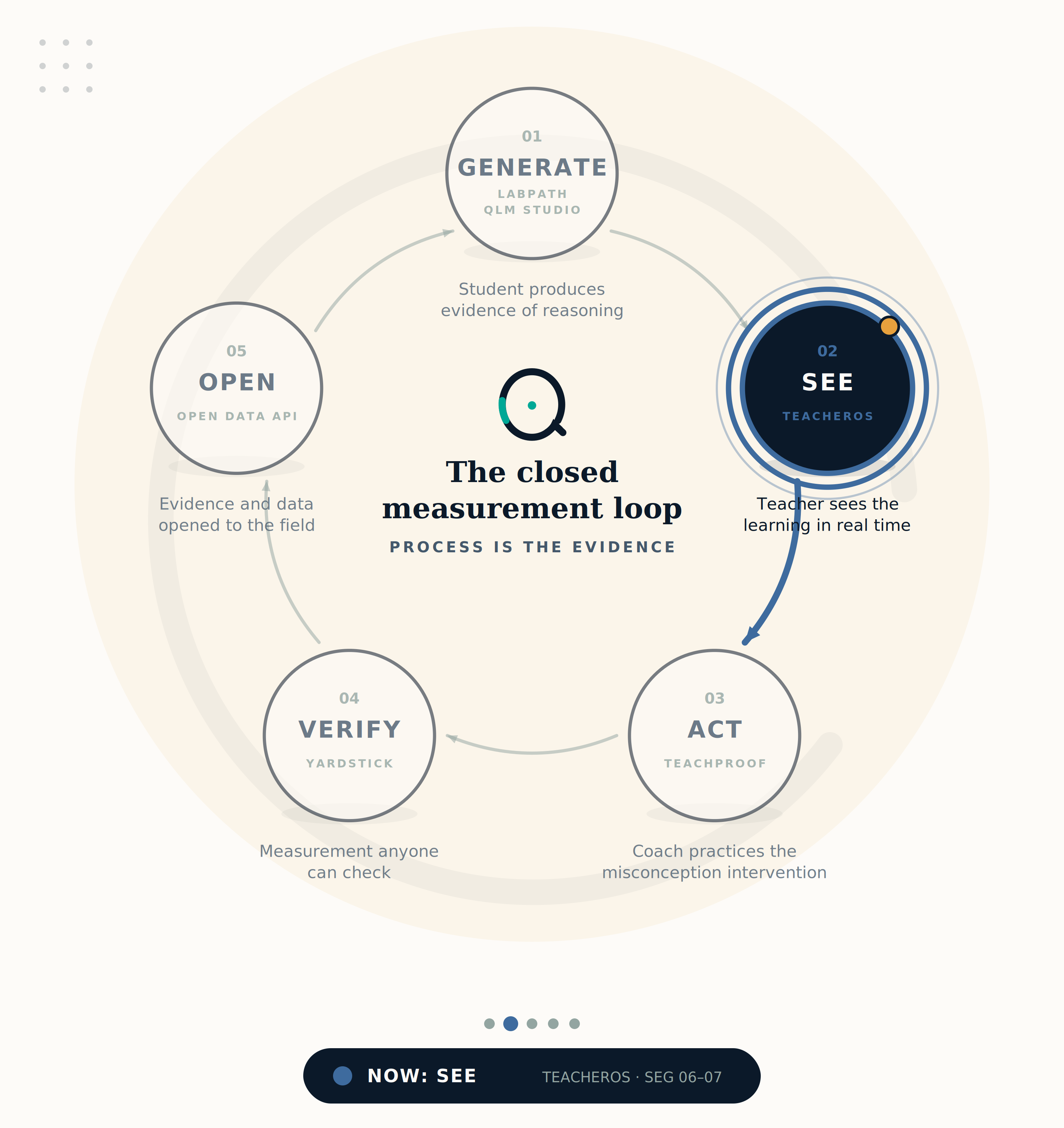
TeacherOS surfaces live evidence dashboards — misconception clusters, revision quality, independence ratios — so teachers see the process, not just the product.
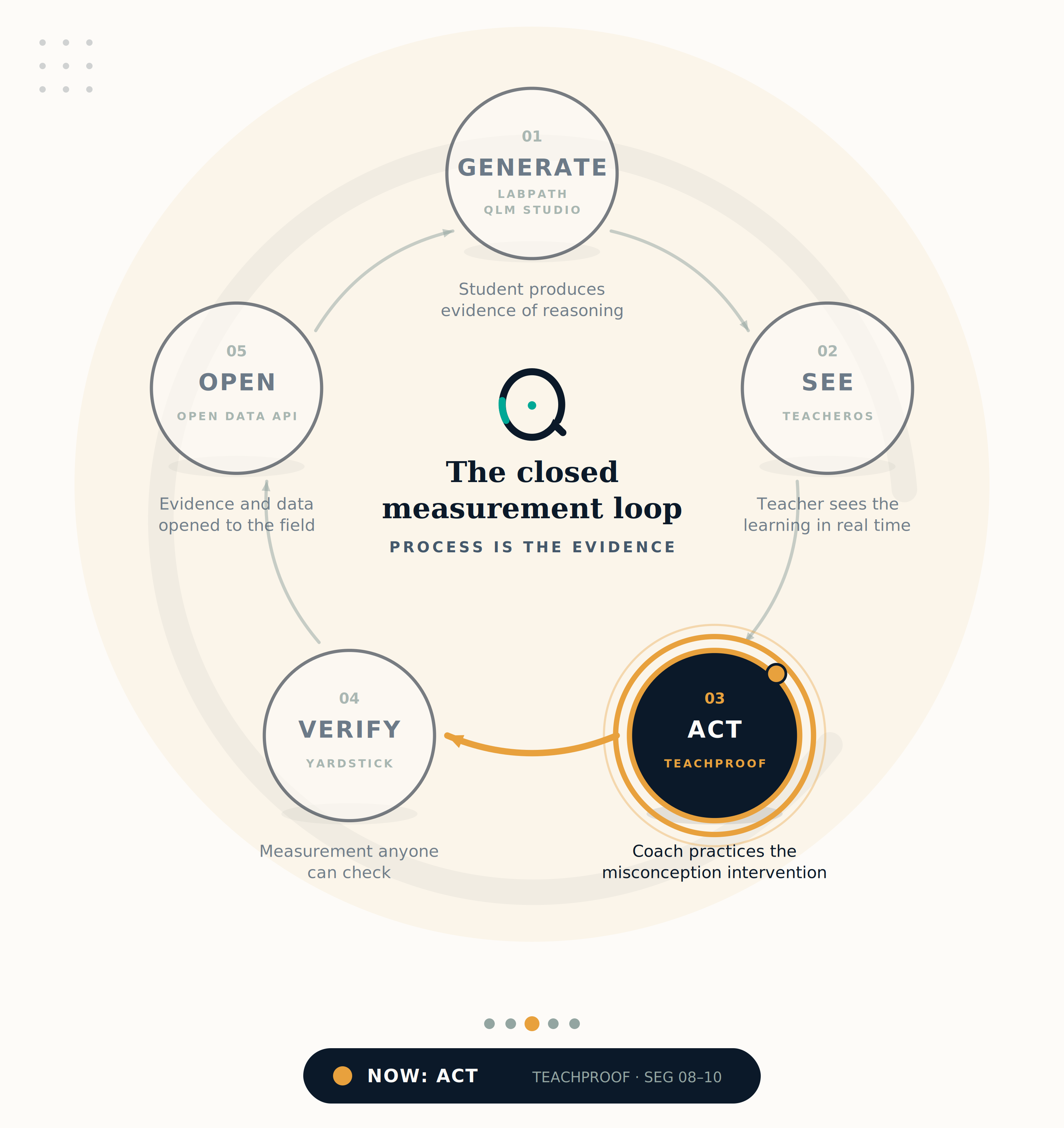
TeachProof lets coaches replay real evidence sessions, practice with AI-avatar students, and refine their moves before the next class. The recording never leaves the vault.
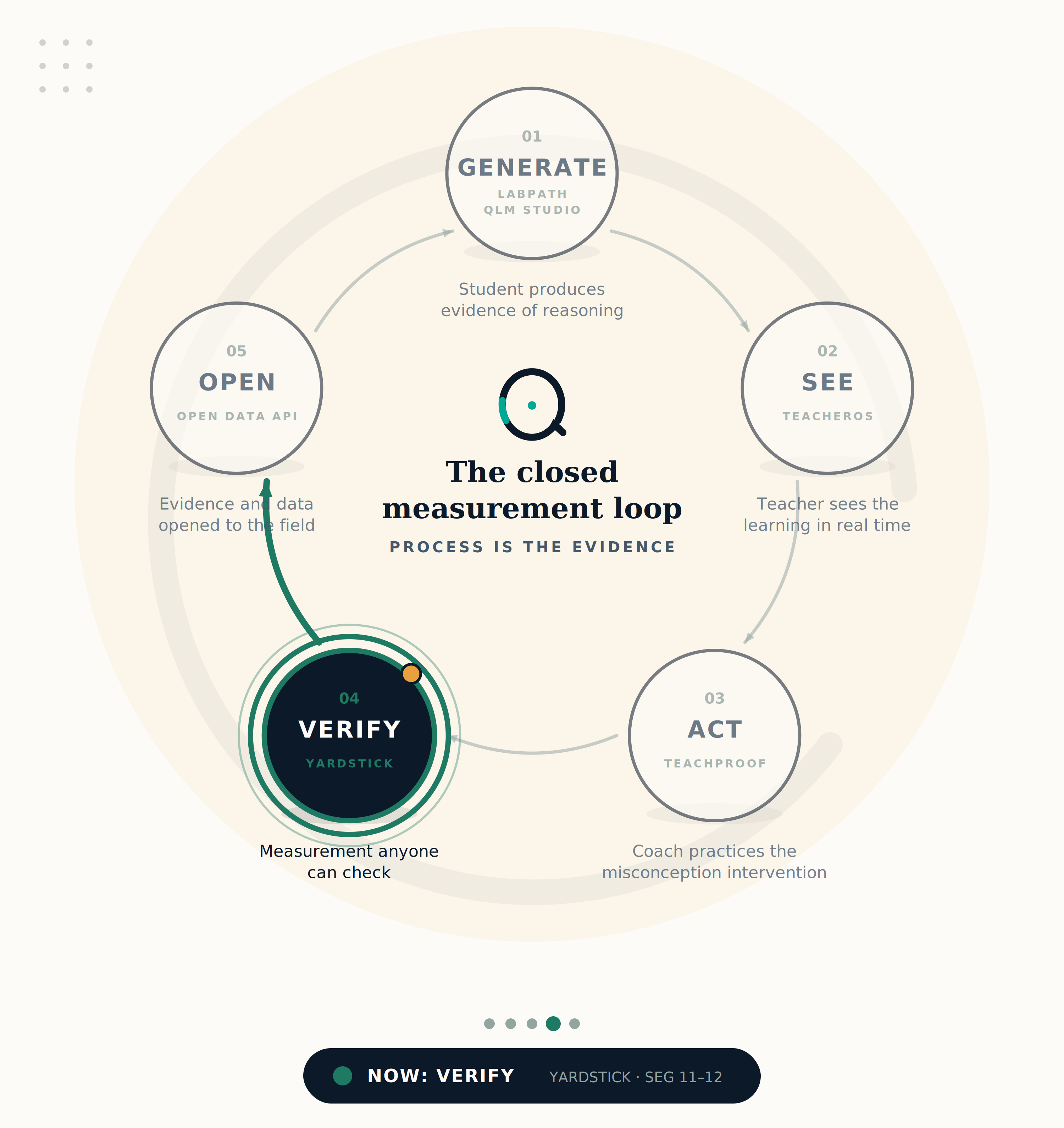
YardStick provides study protocols, verifiable JSONL evidence records, and the SDK verifier — so anyone can audit the measurement trail without our involvement.
423 constructs (CC-BY-4.0), learning-graph crosswalks, standards alignment, and the qlm-measure SDK — open infrastructure the whole field can build on.
No single company should own the measurement layer.
Why open education AI needs one more layer — and what it is made of.
5 questions for any vendor — including us.
423 misconception constructs, learning graph, standards crosswalks.
Emit, run, and consume measurement from any tool.
Limitations first — including numbers we are not proud of.
A practical guide for school leaders evaluating AI tools.
Our model cards lead with what our models cannot do — including numbers we are not proud of. A measurement company that hides its own measurements is a contradiction.
See model cards on HuggingFace →